Nous Research Unveils NousCoder-14B: A High-Performance Olympiad Programming Model Fine-Tuned on Qwen3-14B Using Reinforcement Learning

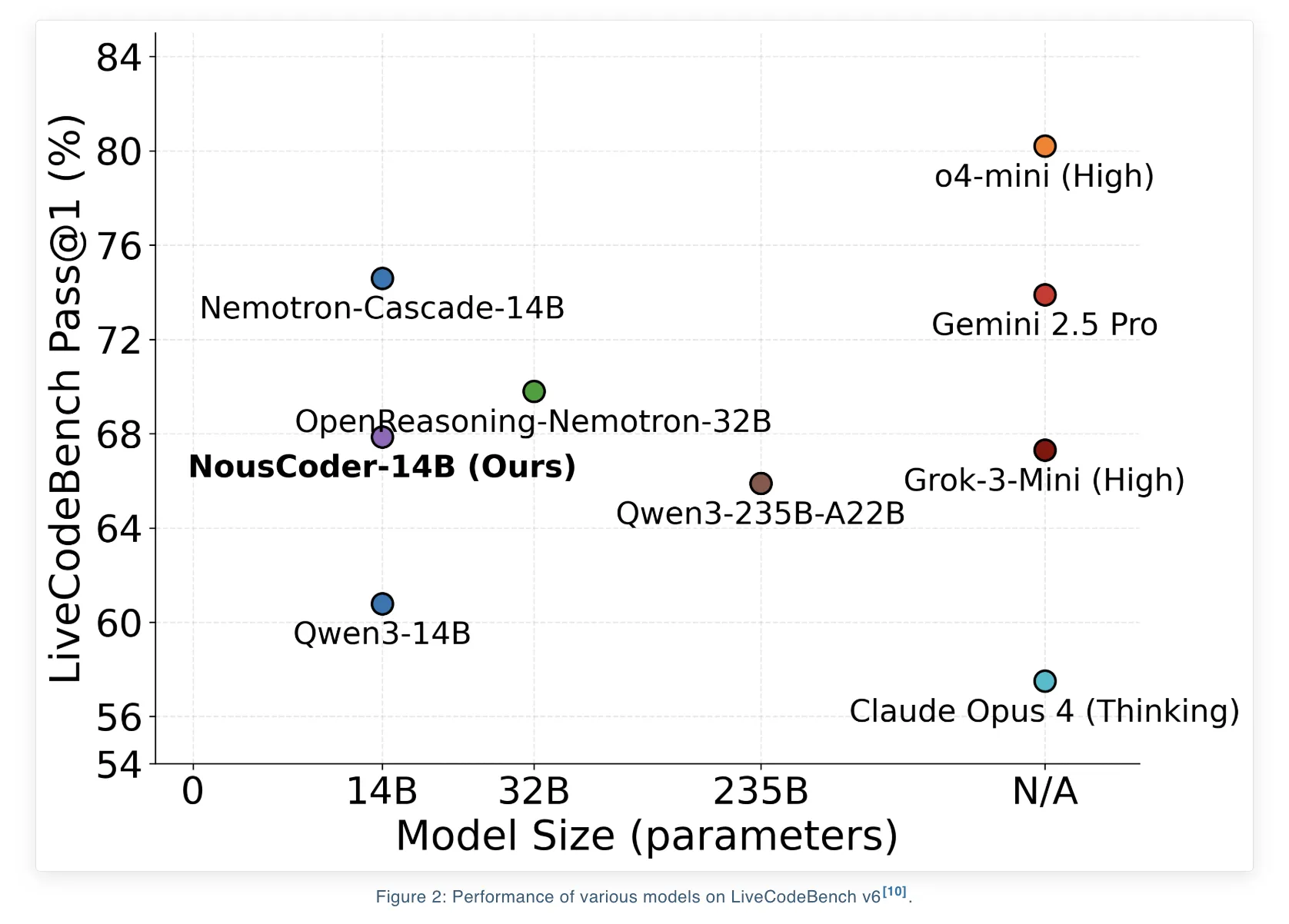
Nous Research has proudly unveiled NousCoder-14B, an advanced programming model specifically designed for competitive olympiad programming. This model has undergone post-training on the Qwen3-14B framework using a method known as reinforcement learning (RL) accompanied by verifiable rewards. The results from LiveCodeBench v6 benchmark, which evaluates problems from August 1, 2024, to May 1, 2025, show that the model has achieved an impressive Pass@1 accuracy of 67.87%. This represents a significant improvement of 7.08 percentage points over the Qwen3-14B baseline, which stood at 60.79% for the same benchmark. To develop this model, the research team meticulously trained it on a dataset of 24,000 verifiable coding problems using an array of 48 B200 GPUs over a period of four days. The model’s weights have been made publicly available under the Apache 2.0 license via Hugging Face.
Benchmark Focus and What Pass@1 Means
The LiveCodeBench v6 benchmark is specifically developed for evaluating competitive programming skills. The test split used in this instance consists of 454 problems. The training set employed follows the same methodology as the DeepCoder-14B project developed by Agentica and Together AI. It merges challenges from TACO Verified, PrimeIntellect SYNTHETIC 1, and LiveCodeBench problems created prior to July 31, 2024.
It is important to note that the benchmark exclusively includes tasks typical of competitive programming. Each problem statement mandates that a solution adhere to strict constraints regarding time and memory usage, while also successfully passing a series of hidden input-output tests. The Pass@1 metric specifically measures the fraction of problems where the first iteration of the generated program successfully navigates through all tests, respecting both time and memory constraints.
Dataset Construction for Execution-Based RL
The datasets used for the training of NousCoder-14B consist of verifiable code generation problems, each accompanied by a reference implementation and multiple test cases. The training dataset is notably extensive, comprising 24,000 individual problems sourced from:
- TACO Verified
- PrimeIntellect SYNTHETIC 1
- LiveCodeBench problems created before July 31, 2024
Furthermore, the test set is made up of LiveCodeBench v6, which includes 454 unique problems spanning from August 1, 2024, to May 1, 2025.
Each problem presents a complete competitive programming task, equipped with a description of requirements, input and output formats, as well as test cases. This structured environment is crucial for the reinforcement learning (RL) process as it produces a straightforward binary reward signal that can be efficiently calculated once the code is executed.
RL Environment with Atropos and Modal
The reinforcement learning environment has been crafted utilizing the Atropos framework. During prompting, NousCoder-14B utilizes standardized formatting as seen in LiveCodeBench prompts and is tasked with generating Python code for each of the queried problems. For every rollout, specific scalar rewards are assigned based on the test case results:
- A reward of 1 is issued when the generated code successfully passes all associated test cases for a specific problem.
- A deduction of -1 is applied when the code outputs any incorrect results or fails to meet the stipulated time or memory limits for any test case.
To safely and efficiently execute untrusted code at a large scale, the team has employed Modal as an orchestrated sandbox solution. Within the primary design specified by the research team, the system launches a single Modal container for each rollout. This container is tasked with executing all test cases relevant to that rollout. Such a design ensures that training compute processes remain separate from verification compute processes, thereby maintaining a stable RL loop.
Furthermore, the research team has streamlined the inference and verification processes. Upon completion of a code generation task by an inference worker, the result is forwarded to a Modal verifier, allowing the worker to immediately initiate a new generation task. This structured approach employs multiple inference workers and a limited pool of Modal containers to ensure the training loop stays bound by inference computations instead of verification factors.
The team critically investigates three parallelization strategies for verification. These range from using one container per problem, one container per rollout, to one for each individual test case. Ultimately, they opted against the per test case approach due to container launch overheads and instead adopted a strategy whereby each container evaluates several test cases while prioritizing a select group of the most challenging test cases. If any of the top tasks fail, the verification process can cease operations early.
GRPO Objectives: DAPO, GSPO, and GSPO+
NousCoder-14B incorporates Group Relative Policy Optimization (GRPO), which negates the need for a distinct value model. Building upon GRPO, the research team explored three additional objectives: Dynamic Sampling Policy Optimization (DAPO), Group Sequence Policy Optimization (GSPO), and an enhanced version of GSPO, referred to as GSPO+.
All three objectives employ a shared definition of advantage, where the advantage for each rollout is reflected through the rewards normalized by the mean and standard deviation of rewards within the grouping. Implementing DAPO introduces importance weighting and clipping at the token level, along with three main modifications compared to traditional GRPO:
- A higher clipping rule designed to boost exploration for low probability tokens.
- A token level policy gradient loss metric that attributes equal weight to each token.
- A dynamic sampling method, which discards groups that are entirely correct or incorrect as they provide no useful advantage.
GSPO, alternatively, shifts the importance weighting focus to the sequence level. It offers a defined ratio for sequence importance which aggregates token ratios over the entirety of the program. GSPO+ retains this sequence level correction while dynamically rescaling gradients, ensuring all tokens receive equal importance irrespective of the length of the sequence.
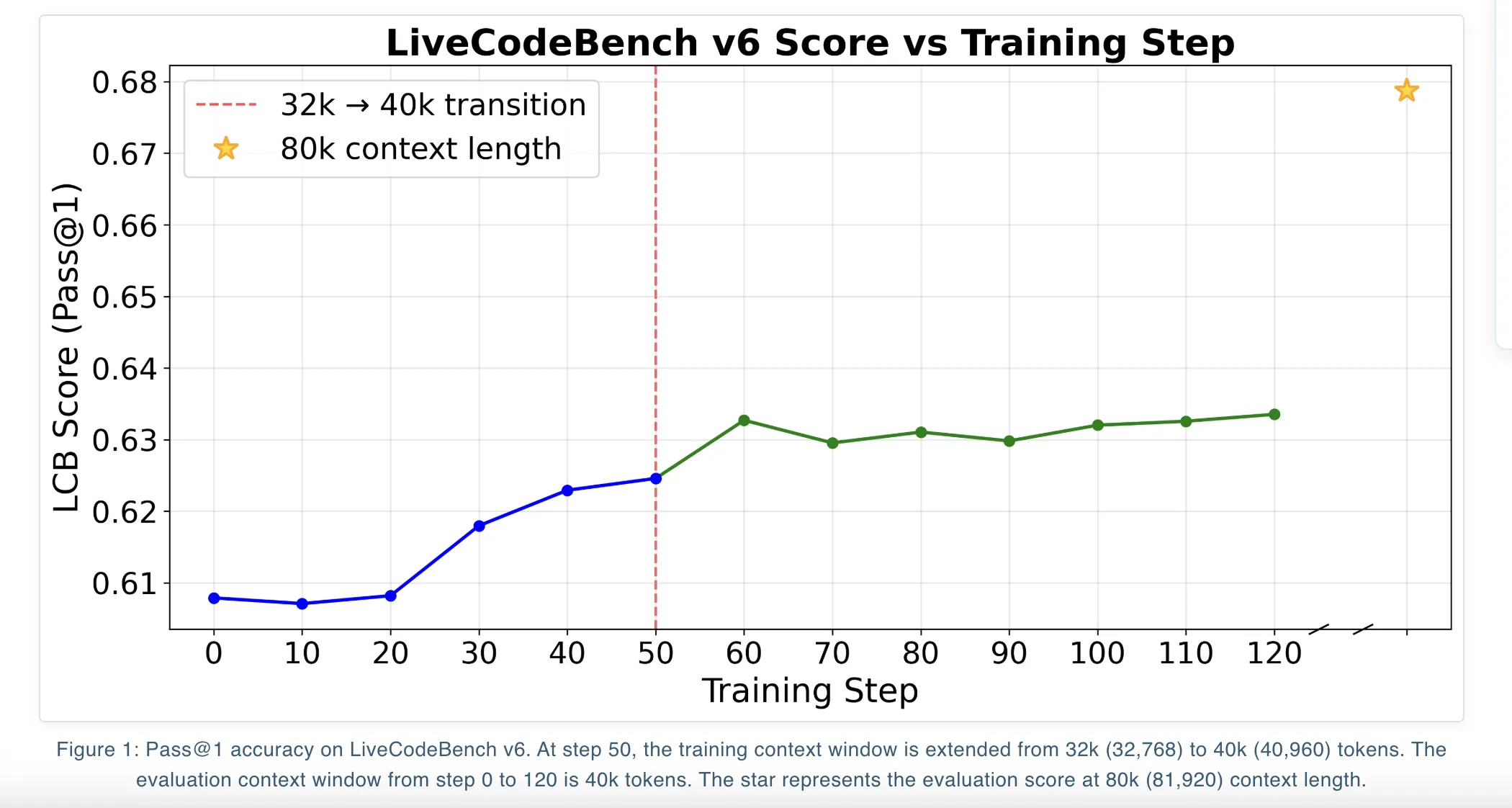
The distinctions in effectiveness among these objectives remain minimal within LiveCodeBench v6. At a context length of 81,920 tokens, DAPO achieves a Pass@1 score of 67.87%, while GSPO and GSPO+ record scores of 66.26% and 66.52%, respectively. When limited to 40,960 tokens, all three objectives hover around a Pass@1 mark of approximately 63%.
Iterative Context Extension and Overlong Filtering
Qwen3-14B facilitates support for long contexts, with training progressing through an iterative context extension schedule. Initially, the model is trained utilizing a 32k context window before advancing to the maximum context window of 40k. Throughout this process, the best-performing checkpoint regarding LiveCodeBench scores at the 40k context is chosen, and during evaluation, a YaRN context extension is applied to extend to 81,920 tokens.
A strategic method called overlong filtering plays a pivotal role. When a newly generated program surpasses the defined maximum context window, its advantage is re-evaluated to zero. This procedure effectively excludes the rollout from the gradient signal instead of penalizing it, supporting the model in avoiding the inclination towards shorter solutions purely for optimization purposes and aiding in maintaining quality during the context length scaling process during tests.
Key Takeaways
- NousCoder 14B is a competitive programming model founded on Qwen3-14B, which has been trained with execution-based RL, yielding a Pass@1 of 67.87% on the LiveCodeBench v6 benchmark. This reflects a notable increase of 7.08 percentage points above the Qwen3-14B baseline set at 60.79%.
- The model underwent training on 24,000 verifiable coding problems sourced from TACO Verified, PrimeIntellect SYNTHETIC-1, and tasks presented prior to July 31, 2024. The evaluation utilized a distinct LiveCodeBench v6 test set comprised of 454 problems spanning from August 1, 2024, to May 1, 2025.
- In the RL setup, the Atropos framework was leveraged, executing Python solutions within sandboxed containers. The reward structure offered a score of 1 for completely solving all test cases while imposing a penalty of -1 for any failures or breaches of resource limitations.
- The Group Relative Policy Optimization objectives, namely DAPO, GSPO, and GSPO+, are utilized for implementing long-context code RL, all perform under normalized group rewards and reveal similar outcomes, with DAPO achieving the highest Pass@1 score at the extended context of 81,920 tokens.
- The training methodology employed an iterative context extension, initially at 32k tokens, then at 40k tokens, and leveraging a YaRN-based extension for evaluation purposes to reach the full context of 81,920 tokens. Progressive filtering for overlong rollouts helps to stabilize this process, with the entire stack being made available for reproducibility, including code under Apache 2.0 licenses.
Discover further details about the Model Weights and Technical Specifications. We also invite you to follow us on Twitter and join our growing community on the 100k+ ML Subreddit. Don’t forget to subscribe to our Newsletter. If you use Telegram, you can connect with us there too!
Asif Razzaq is the CEO of Marktechpost Media Inc. Driven by a vision as an entrepreneur and engineer, Asif is dedicated to leveraging the potential of Artificial Intelligence for the greater good. His latest venture encompasses the launch of an AI-focused media platform, Marktechpost, which excels in delivering in-depth insights into machine learning and deep learning trends. The platform has garnered over two million monthly views, indicating its prominence among the audience.

Jessica
https://www.linkedin.com/company/aucteraAffiliate Content Writer